The Convergence
Three independent teams just validated the same architectural insight: Google ADK (3 days ago):“Context is a compiled view over a richer stateful system.”Stanford/SambaNova ACE paper (October 2025):
“Treat contexts as evolving playbooks that accumulate, refine, and organize strategies.”Squad (months ago, in production):
“We learned this a few months ago when building our active context management systems.”When Google’s agent framework team, Stanford researchers, and a startup building multi-agent systems all independently arrive at the same architecture, that architecture is probably correct.
The Problem We Hit
Month 1 of Squad:The Wrong Mental Model
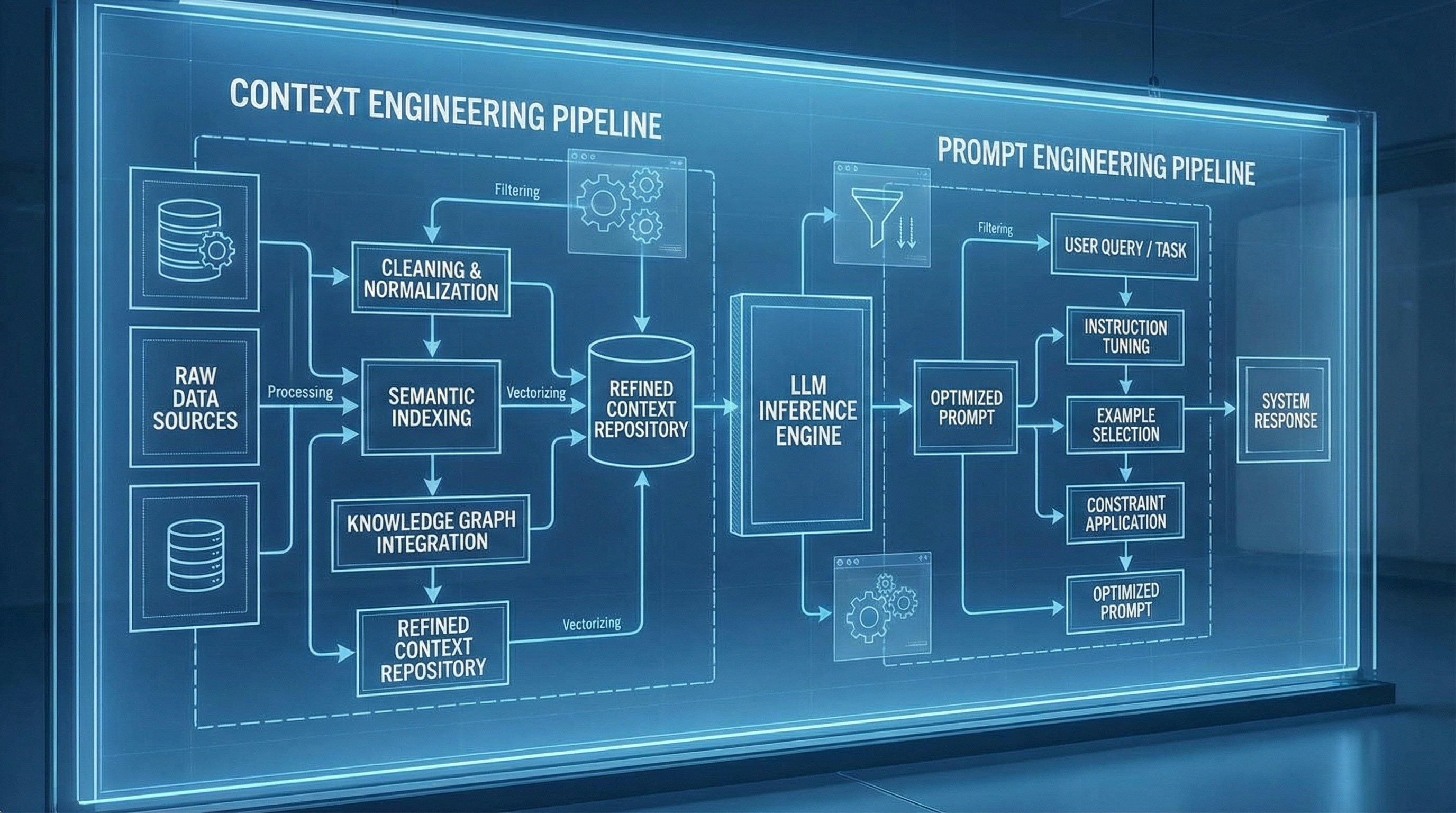
Most agent frameworks handle context like this:The Compiler Mental Model
Source code (what you store):- Sessions
- Memory
- Artifacts (files)
- Full structured state
- Named processors
- Sequence of passes
- Observable transformations
- Working context
- Minimal, relevant, scoped to this call
Squad’s Three-Tier Architecture
The Multi-Agent Identity Fix
Wrong: Pass Agent A’s conversation to Agent B as history. Right: Transform Agent A’s outputs into context FOR Agent B.- Scout’s outputs become Engineer’s context, not history
- Clear attribution: “Scout found…” not “I found…”
- No identity confusion
- Before: 39% identity confusion
- After: 2% identity confusion
Evidence: Before vs After
Before Context Engineering (Month 1-2)
| Metric | Value |
|---|---|
| Average context size | 180K tokens |
| Context relevance | 34% |
| Identity confusion | 39% |
| Task success rate | 61% |
| Cost per task | $2.40 |
After Context Engineering (Month 4+)
| Metric | Value | Change |
|---|---|---|
| Average context size | 48K tokens | -73% |
| Context relevance | 91% | +168% |
| Identity confusion | 2% | -95% |
| Task success rate | 94% | +54% |
| Cost per task | $0.77 | -68% |
The Reach, Don’t Flood Principle
Google’s ADK: “Agents should reach for information via tools, not get flooded with everything upfront.”- 75% token reduction
- +3.2 tool calls per task (agents reaching for what they need)
- 94% task success rate
- 68% cost reduction
This is a scaffold post. Full content will include:
- Complete compilation pipeline code
- Processor architecture details
- Google ADK comparison table
- Stanford ACE paper insights
- Meta MSL validation
- Practical implementation guide
The Meta-Point
Four independent teams arrived at the same architecture:| Principle | Google ADK | ACE Paper | Meta MSL | Squad |
|---|---|---|---|---|
| Storage ≠ Presentation | Sessions vs Working Context | Playbooks vs Delta Updates | Environments vs Evaluations | Tiers vs Compiled View |
| Explicit Transformations | LLM Flows + Processors | Generator → Reflector → Curator | Verifier Pipeline | Named Processor Chain |
| Scope by Default | Tools reach for more | Incremental updates | Constraint-scoped | Protocol-based access |
Related Reading: